ElasticSearch
aliases:
- elasticsearch 标题: elasticsearch
ElasticSearch分片以及副本
笔记本: elasticsearch
创建时间: 2023/11/10 16:08 更新时间: 2023/11/10 16:11
ElasticSearch分片以及副本
分片(Shard)以及副本(Replica)
分布式存储系统为了解决单机容量以及容灾的问题,都需要有分片以及副本机制。Elasticsearch
没有采用节点级别的主从复制,而是基于分片。它当前还未提供分片切分(shard-splitting)的
机制,只能创建索引的时候静态设置。
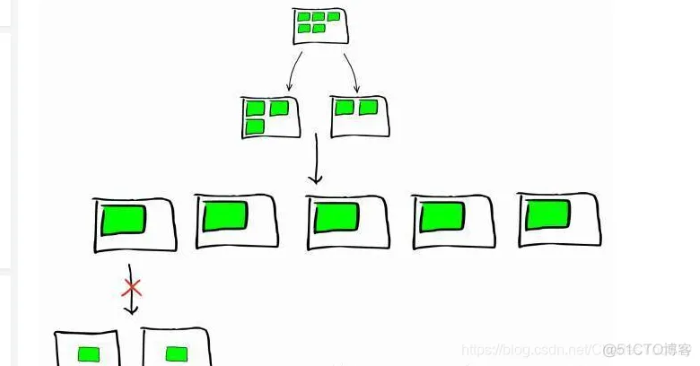
比如上图所示,开始设置为5个分片,在单个节点上,后来扩容到5个节点,每个节点有一个分
片。如果继续扩容,是不能自动切分进行数据迁移的。官方文档的说法是分片切分成本和重新索
引的成本差不多,所以建议干脆通过接口重新索引。
Elasticsearch 的分片默认是基于id 哈希的,id可以用户指定,也可以自动生成。但这个可以通
过参数(routing)或者在mapping配置中修改。当前版本默认的哈希算法是MurmurHash3。
Elasticsearch 禁止同一个分片的主分片和副本分片在同一个节点上,所以如果是一个节点的集
群是不能有副本的。
为什么要考虑分片
如果你刚接触ElasticSearch, 那么弄清楚它的几个术语和核心概念是非常必要的.
假设ElasticSearch集群的部署结构如下:
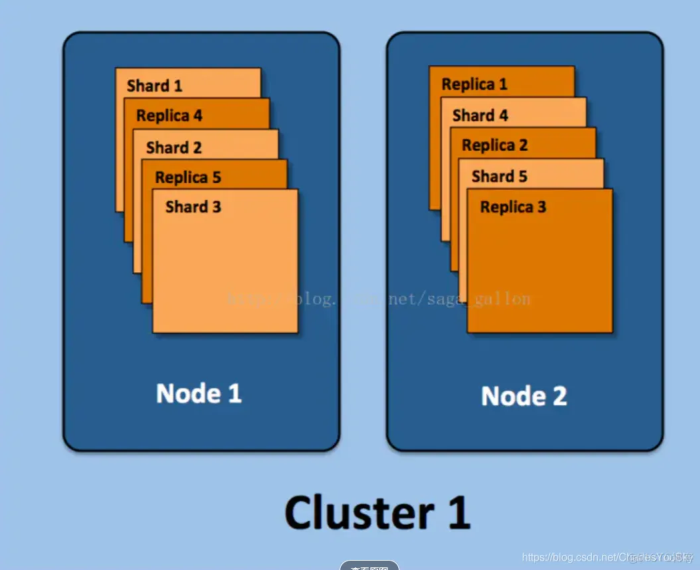
集群(cluster) :由一个或多个节点组成, 并通过集群名称与其他集群进行区分
节点(node) :单个ElasticSearch实例. 通常一个节点运行在一个隔离的容器或虚拟机中
索引(index) :在ES中, 索引是一组文档的集合
分片(shard) :因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配,所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是20亿.
副本(replica) :ES默认为一个索引创建5个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个copy.对于分布式搜索引擎来说, 分片及副本的分配将是高可用及快速搜索响应的设计核心.主分片与副本都能处理查询请求, 它们的唯一区别在于只有主分片才能处理索引请求.在上图示例中, 我们的ElasticSearch集群有两个节点, 并使用了默认的分片配置. ES自动把这5个主分片分配到2个节点上, 而它们分别对应的副本则在完全不同的节点上. 对,就这是分布式的概念.
副本作用
副本分片的主要目的就是 为了故障转移以及实现负载均衡 ,正如在 集群内的原理 中讨论的:如果持有主分片的节点挂掉了,一个副本分片就会晋升为主分片的角色。在索引写入时,副本分片做着与主分片相同的工作。新文档首先被索引进主分片然后再同步到其它所有的副本分片。增加副本数并不会增加索引容量。无论如何,副本分片可以服务于读请求,如果你的索引也如常见的那样是偏向查询使用的,那你可以通过增加副本的数目来提升查询性能,但也要为此 增加额外的硬件资源。搜索性能取决于最慢的节点的响应时间,所以尝试均衡所有节点的负载是一个好想法。 如果我们只是增加一个节点而不是两个,最终我们会有两个节点各持有一个分片,而另一个持有两个分片做着两倍的工作。
倒排索引原理
笔记本: elasticsearch
创建时间: 2023/11/10 15:58 更新时间: 2023/11/10 16:01
分布式搜索引擎ElasticSearch之 倒排索引原理
倒排索引原理
ES采用的是倒排索引(Inverted Index), 也称为反向索引。 有反向索引,也会有正向索
1. 正向索引
正排索引是以文档的ID作为关键字,并且记录文档中每个字段的值信息,通过查询id来把
拿出来。
但是在查询某一个keyword存在于哪些文档的时候, 需要对所有文档进行扫描匹配。这
率比较低下。
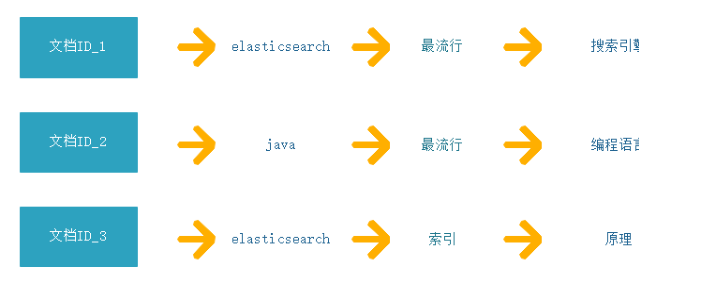
2. 倒排索引
倒排索引以字或词作为关键字索引, 倒排索引建立的是分词(Term)和文档(Document)之间的映射关系。
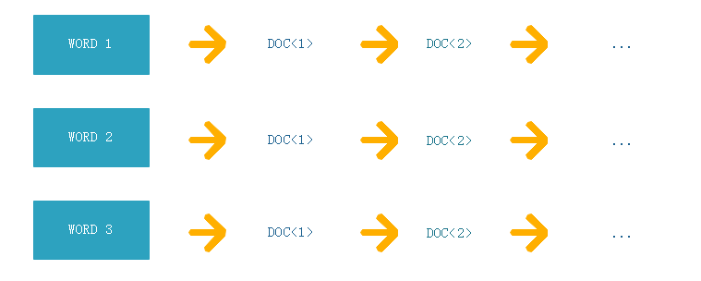
倒排索引表结构, 去除停用词后构造的倒排索引:
倒排索引主要由单词词典(Term Dictionary)和倒排列表(Posting List)及倒排文件(Inverted File)组成。
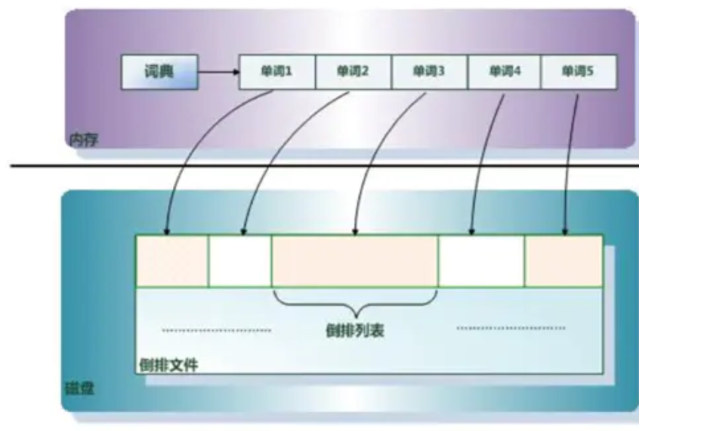
单词词典(Term Dictionary): 搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合。 **倒排列表(PostingList):**倒排列表记载了出现过某个单词的所有文档的文档列表,以及单词在该文档中出现的位置信息及频率,每条记录称为一个倒排项(Posting)。 **倒排文件(Inverted File):**所有单词的倒排列表按顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
3. 如何定位
对于规模很大的文档集合,里面可能包含上百万的关键单词(term), 找出某个特定的te
慢, 需要逐个过滤一遍,如何快速定位?
先做好排序,然后用二分查找的方式,这样比全部遍历方式来得更快,这个就是term
dictionary。可以采用logN次磁盘查找获取目标,但是磁盘随机读操作仍然非常昂贵(一
读random access 大概需10ms),
所以尽量少读磁盘, 但缓存到内存中, 整个term dictionary又非常大, 于是就有了ter
字典的索引。
term index 是b-tree结构:
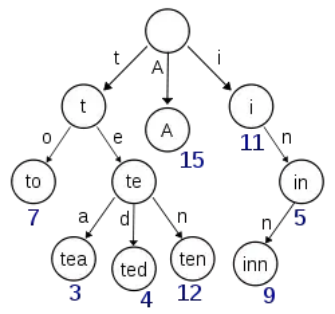
这棵树不会包含所有的term,它只记录term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
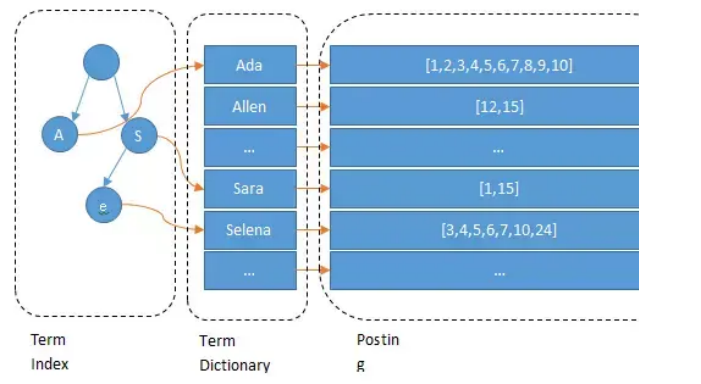
所以term index不需要存储所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。